What Are Tokens — And Why Should You Care?
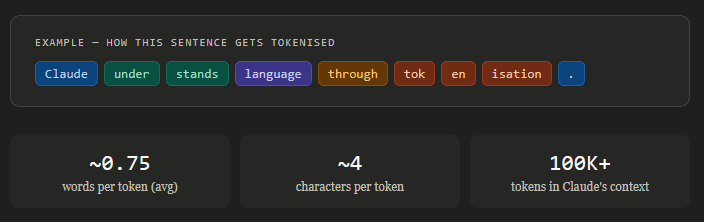
The hidden unit of measurement that shapes every conversation you have with Claude. You type a message to Claude. You hit send. A response flows back in seconds. Simple, right? But beneath that seamless exchange, something interesting is happening — your words are being sliced into tiny linguistic units called tokens before Claude ever "reads" them. Tokens are the atomic unit of language for large language models. They're not characters, and they're not always full words. They sit somewhere in between — and understanding them unlocks a clearer picture of how AI language models actually work, why they have limits, and how to work with those limits instead of against them. So what exactly is a token? Think of tokenisation as breaking text into the most useful chunks for a model to learn from. Common words like "the" or "and" are usually one token. Longer or rarer words might get split into two or three pieces. Punctuation, spaces, and newlines all count too. Example — how this sentence gets tokenised Claude under stands language through tok en isation . As a rough rule of thumb: 100 tokens is about 75 words, or a short paragraph. A typical novel runs around 100,000 words — that's roughly 133,000 tokens. Claude's extended context window can hold the equivalent of several books at once. The context window: Claude's working memory Every conversation with Claude happens inside a context window — a fixed-size buffer that holds everything Claude can "see" at once. This includes your entire conversation history, any documents you paste in, system instructions, and Claude's own responses. Once the window fills up, older content scrolls out of view. Claude doesn't forget it in the human sense — it simply can't read past what fits. This is why very long conversations can occasionally feel like Claude loses track of something said much earlier.
With over 9 years of experience as in IT, I have led technology operations across diverse industries, ensuring robust IT infrastructure, network security, and team development.
My expertise spans managing IT infrastructure & operations, IT policy, and backup/disaster recovery. My expertise also includes IT asset management, Google Workspace & Office 365, endpoint security, DLP, and cross-platform systems (Windows/Linux/Mac OS) etc.
Additionally, I hold certifications in Google IT Support, CCNA, and IBM Cybersecurity, reinforcing my commitment to continuous learning and delivering robust technology solutions.
Thank you for your time and consideration.
Best regards, Vishal Mathur
✦ Watch output length
If you need a detailed response, say so. If you need a brief one, say that too — it saves tokens and gets to the point faster.
As a rough rule of thumb: 100 tokens is about 75 words, or a short paragraph. A typical novel runs around 100,000 words — that's roughly 133,000 tokens. Claude's extended context window can hold the equivalent of several books at once.
The context window : Claude's working memory
Every conversation with Claude happens inside a context window — a fixed-size buffer that holds everything Claude can "see" at once. This includes your entire conversation history, any documents you paste in, system instructions, and Claude's own responses.
Once the window fills up, older content scrolls out of view. Claude doesn't forget it in the human sense — it simply can't read past what fits. This is why very long conversations can occasionally feel like Claude loses track of something said much earlier.
Tokens flow in both directions. The messages you send are input tokens; the words Claude writes back are output tokens. Both count toward usage — which is why a long document you paste in, plus a detailed response, can add up quickly.
Why does this matter in practice?
For most everyday use — asking questions, drafting emails, writing code — you'll never hit a limit. But for power users working with large documents, long research threads, or complex multi-step tasks, token awareness becomes a practical skill.
✦ Be concise in prompts | Shorter, well-targeted prompts leave more room for Claude's response and keep costs lower on API usage. | |
✦ Paste selectively | When working with documents, paste only the relevant sections rather than the entire file. | |
✦ Summarise long threads | If a conversation is getting long, ask Claude to summarise key points — then start fresh with that summary as context. | |
✦ Watch output length | If you need a detailed response, say so. If you need a brief one, say that too — it saves tokens and gets to the point faster. |
Tokens and pricing on the API
If you're building with Claude via the API, tokens are the billing unit. You pay for what you consume — input and output separately. This makes token efficiency a real engineering consideration: a well-crafted system prompt that's 200 tokens instead of 800 can meaningfully reduce costs at scale.
Different Claude models have different context limits and pricing tiers. Claude Sonnet 4.6, for instance, balances capability and efficiency for everyday tasks, while Opus 4.6 offers more reasoning depth for complex work — at a higher token cost.
The bigger picture
Tokens aren't just an implementation detail — they're a window into how language models perceive text. Claude doesn't read your words the way you do. It processes sequences of these sub-word units, learning statistical patterns across billions of them during training. The quality of that training, across an enormous token vocabulary, is what gives Claude its fluency.
Next time you're mid-conversation and something feels slightly off — a long document Claude seems to have "forgotten," or a response that got truncated — there's a good chance tokens are the explanation. And now you'll know exactly why.


